Some media files appear to block the encoding queue. This is probably due to some corrupted or unsupported media files. The result is a runaway ffmpeg process that never ends, thus blocking the encoding queue. This is reproducible, when using the same “corrupted” source file.
The current setup is that the Batch server tries in succession 3 different encoders (ffmpeg, ffmpeg-aux, and mencoder). It tries the whole succession 3 times before giving up. The trouble is that at some point one of the tries just hangs, never ending, thus blocking the processing queue on this server
The problem is, once all batch servers are in a deadlock, new jobs don’t go through anymore.
My question is: are the runaway processes automatically killed somehow after some time? Or do I have to set up some monitoring to address this?
When you say “The result is a runaway ffmpeg process that never ends, thus blocking the encoding queue”, can you please provide the log for this job? As you said, we have two fallback transcoding mechanisms in the event the lead ffmpeg binary failed to perform the transcoding: ffmpeg-aux, which is just an older version of ffmpeg and mencoder. In the event ffmpeg failed, the other two will usually fail as well but in some cases, it’s worth a try which is why it is done.
At any rate, once all three tried and failed to transcode all the pre-defined transcoding flavours in the set, the job should be marked as failed and no further attempts should be made. Need to understand why this is not happening in your case.
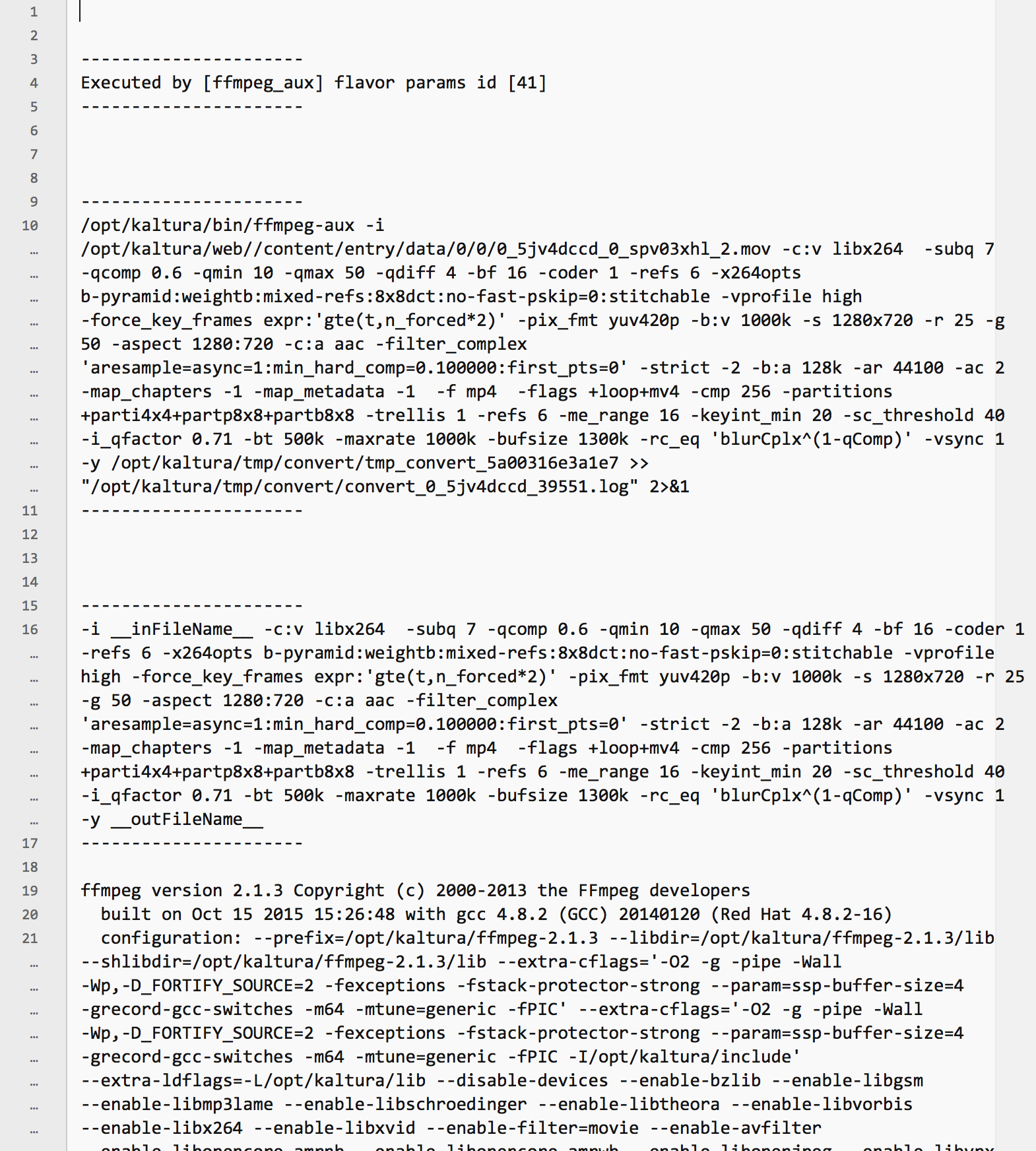
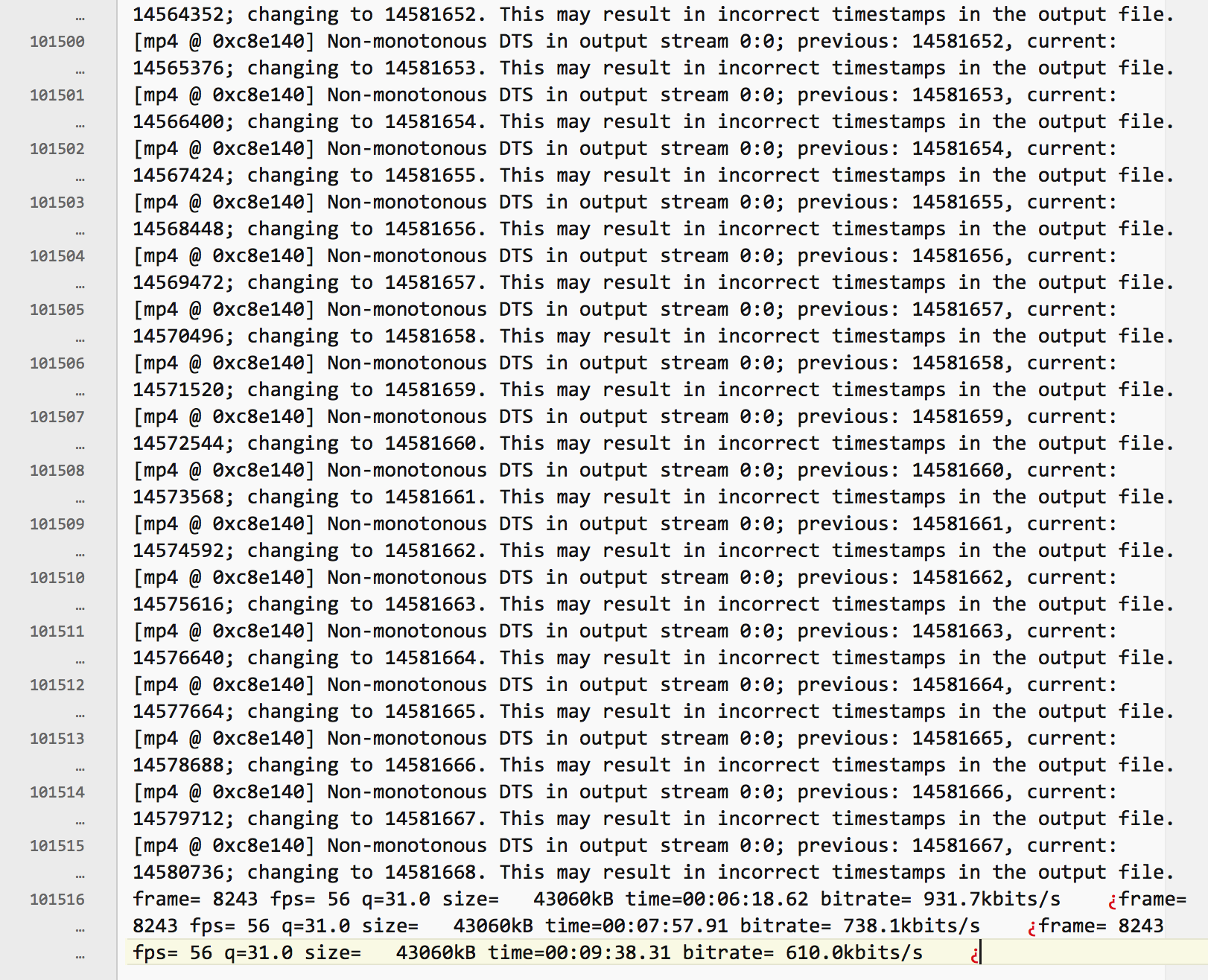
The details of task ID show no log file (“Log File Sync Local Path”) but there is a “convert_0_5jv4dccd_39551.log” file in /opt/kaltura/tmp/convert . This file seems to belong to this job (media ID is “0_5jv4dccd” indeed) but has not been modified for more than 6 hours now. It shows as expected (from the above workflow picture) a running log for ffmpeg-aux.
It would also be helpful if you could open a trial account on our SaaS [https://corp.kaltura.com/free-trial] and check whether this can be reproduced there. If so, it’ll be easier for us to debug.
Thanks for the offer ! I’m sending the logs to you via email. I also created a trial account on your SaaS but I couldn’t reproduce the problem, i.e. the faulty video file was processed – the resulting video, even though obviously corrupted, transcoded and played fine.