I’ve run an upgrade on all the nodes of my not-yet-in-production production cluster. The update was done following these instructions, except for the yum clean all parts. They seem to extend the update time with perhaps negligible value.
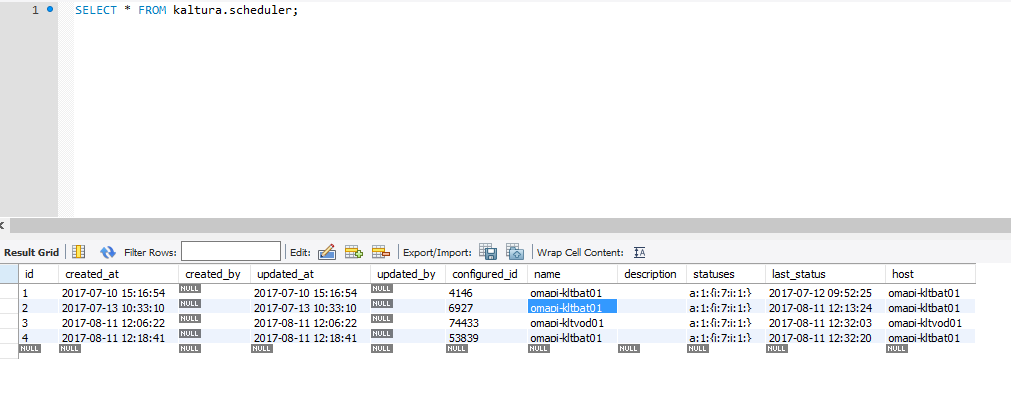
It seems after upgrading I have duplicate entries in the kaltura.scheduler table. There should only be two, but there are four listed there.
I have two batch servers, but of the four items in the table, three reference one server which is terribly odd.
So, I guess my question is, assuming this is incorrect, how would I go about fixing it?
Is there anything wrong here or is it just a clean up thing?
Is it required that you do this if you upgrade?
Are there other situations where this would happen?
I assume after you’ve truncated these tables, you simply restart ALL batch nodes using kaltura-batch.sh ?
is nothing wrong, the thing is that you have to backup your batch.ini before an upgrade, and then you will preserve the same batch ID, if you generate a new batch.ini then the batch ID will change and you will see your batches duplicated.
the truncate will help you see the actual batches that you currently have running.
after the truncate you just have to run in your batch servers:
service kaltura-batch restart
if you use a RHEL based system.
and then all the 4 tables will be populated again.